Совместимость русских и европейских шрифтов в сети Интернет
В статье приводится исследование вопроса на примере русско-французских страниц HTML,
предназначенное для массового пользователя, знакомого с основами HTML
и создающего многоязычные HTML-страницы как от нуля,
так и на основе документов, подготовленных в PageMaker, Word и др.
Опубликовано в журнале
"Мир Интернет", N 6-7, 2000, с.78-84.
Добавление через полтора года (осень 2001)
С удовольствием отмечаю, что статья в значительной части устарела:
- Netscape 6 (причем оба - и навигатор, и композер) избавился от фатальной несовместимости
- Internet Explorer 6 избавился от неумения печатать смешанные страницы
- AceHTML 4.30 научился лихо управляться с редактированием кода смешанных текстов
- FrontPage 2000
тоже теперь понимает, что от него хотят, и делает это
Однако основные приемы подготовки HTML-страниц остаются в силе.
Многие проблемы еще остались (в частности, написание многоязычных серверных скриптов в принципе возможно, но чрезвычайно громоздко. Речь идет о сервере, на котором находится этот файл)
|
Web-версия статьи, подготовленная Д.Л., несколько отличается от журнальной
по содержанию и верстке.
Тема требует особо тонкого отношения к шрифтам и кодировкам и
поэтому, чтобы гарантировать читаемость для широкого круга пользователей
независимо от настроек их навигаторов*,
мы все буквы, не входящие в русский и английский алфавит, передаем
экзотическим, но самым надежным способом, в самой статье вообще не упомянутым: в виде gif-картинок.
(Правильнее было бы назвать английский "латинским", что вернее с точки зрения языка,
или "американским", что точнее отражает суть разбираемого вопроса.
Главное - он весь в первой половине классической 256-символьной таблицы).
Не забудьте включить показ графики !
*) Навигатор - то же, что и броузер, но с французским акцентом.
- Что ты, Гек, да разве французы говорят не по-нашему ?
- Да, Джим, ты бы ни слова не понял!
- А француз человек или нет?
- Человек.
- Так почему же, черт возьми, он не говорит по-человечески ?
М.Твен. Приключения Гекльберри Финна.
Оглавление
Для удобства читателей отмечаем в оглавлении знаком "!!" и жирным шрифтом
путь к сокращенному чтению - важнейшие разделы, имеющие к тому же справочный характер.
Откуда взялась проблема
Как сделать web-страничку, на которой благополучно уживались бы русский и
французский языки, причем вместе - в одном файле, как это, например,
происходит в учебнике, словаре или комментариях к текстам песен?
Такой вопрос встает далеко не только в отношении совмещения русского и
французского языков, но и, например, немецкого и украинского и т. п., то есть
когда вместе идут два текста - один на латинской основе с диакритическими
знаками, другой - на кириллице.
Впервые эта проблемой возникла при попытке одного из авторов (Д.Л.) поместить в Сети
главы из своего учебного пособия "Французский язык для физиков" году в 1998.
События развивались по классической схеме "нос вытащили - хвост увяз",
то есть как только казалось, что к русским буквам удалось присоединить французские,
русские тут же куда-то исчезали, а потом все происходило с точностью до наоборот.
Что же делать, если мы хотим видеть оба текста вместе... а как иначе в словаре и учебнике?
Не создавать же два параллельных фрейма! (впрочем, почему бы и нет ... иногда можно).
Ни один специалист и ни одна книжка не говорили ничего путного, и стало ясно, что
между кириллицей и латиницей с диакритическими знаками
проходит недокументированная пропасть. Фундаментальный web-самиздат давал массу
решений по поводу русификации, при этом тактично обходя "европу", а искать
русский ответ в западноевропейской сети оказалось и вовсе делом безнадежным.
Тем не менее ответ нашелся. Сначала только один и только для IExplorer, потом все больше и больше ...
Простейшие HTML - страницы
Французский с нижегородским ... отдельно
Правильное представление русского текста в HTML не вызывает трудностей.
Все исчерпывается установкой подходящего шрифта со стороны пользователя, а со
стороны сайта - корректным указанием кодировки в файле HTML (или ее подбором
самим пользователем). То же относится и к французскому языку. Главное с обеих
сторон - как веб-мастеру, так и пользователю - не злоупотреблять
экзотическими шрифтами, поскольку в них может не оказаться нужных букв. Для
надежности лучше вообще не указывать шрифт (то есть убрать все теги
<FONT FACE=...>). Если пользователю все равно, то у него скорее
всего по умолчанию используется самое живучее и универсальное сочетание
Times + Courier, а если очертания букв ему действительно
небезразличны, то пусть сам и разбирается.
Текст HTML-документа набирается в этом случае обычным образом "буква в
букву" без каких-либо кодировочных ухищрений, например:
<HTML >
<HEAD>
<TITLE>Русский текст</TITLE>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=KOI8-R">
</HEAD>
<BODY>
Французское лето
</BODY>
</HTML>
<HTML>
<HEAD>
<TITLE>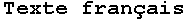 </TITLE>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=windows-1252">
</HEAD>
<BODY>
</TITLE>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=windows-1252">
</HEAD>
<BODY>
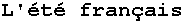 </BODY>
</HTML>
</BODY>
</HTML>
Все просто, но никаких смешанных текстов воспроизвести не получится. Что
же делать, если они все-таки нужны?
Нулевой вариант
Конечно, самый простой способ избавиться от проблемы - просто
игнорировать ее. Вспомним, что в русском языке отсутствие двух точек над
буквой "е" практически никогда не приводит к искажениям смысла, и стало
повседневной нормой. Даже отсутствие галочки над й, хотя и раздражает, но
не мешает пониманию текста. Однако во французском языке буквы с accents (они
же "буквы с диакритическими знаками") весьма многочисленны и, хотя при
отсутствии accents смысл обычно легко восстанавливается, такое недопустимо в
хорошем литературном языке, а тем более в учебнике или словаре.
С этой точки зрения требования к страницам HTML гораздо выше, чем к
электронной почте с ее откровенным лаконизмом (вспомним наши телеграммы без
предлогов и союзов). Однако закроем вопрос с электронной почтой тем, что
посоветуем вообще забыть про accents - в противном случае можно долго
объяснять, что "и так тоже не получится".
Простое многоязычное решение
Проблемы возникает из-за того, что документ HTML - это обычно простой
текстовый файл, и в зависимости от примененной кодировки и установленного
шрифта один и тот же код символа в файле может представляться на экране и как
русская, и как французская буква. В отличие от документов MS Word, в пределах
одного документа HTML допустима только одна кодировка. Поэтому возникают
многочисленные способы передачи одной буквы комбинацией нескольких символов.
Простейшее решение состоит в следующем:
- русский текст набирается буква в букву ;
- французские буквы с accents передаются цепочками вида é (см. приложения);
- кодировка явно указывается как кириллица: (Windows-1251, KOI8-R и т. д.) ;
- при просмотре в Internet Explorer используется шрифт, содержащий все необходимые символы;
- при переходе в другую русскую кодировку французская часть остается неизменной.
Пример:
<HTML>
<HEAD>
<TITLE> Русско-французский текст </TITLE>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=KOI8-R">
</HEAD>
<BODY>
<P> Французское лето
<P>L'été français
</BODY>
</HTML>
К преимуществам этого метода относятся хорошая читаемость HTML-кода и
незначительное увеличение объема файлов: замена é на é
удлинняет текст всего на 10-20%.
Однако у этого метода есть и серьезный недостаток - он неприменим для
Netscape Navigator. Будь он пригоден и для Netscape, вопрос можно было бы
считать закрытым, однако это не так, и мы идем дальше, пытаясь примирить
между собой разнообразие программ и кодировок.
Читатель, не желающий погружаться в теорию, может переходить к
практическому разделу Варианты записи букв
Кодировки и их использование
Суть вопроса
Корень проблемы лежит, видимо, в менталитете разработчиков ОС, HTML и пр.
, которые изначально предусмотрели место только для одного языка -
английского. Все остальные считались иностранными и пристыковывались на
костылях. Ну, а два или три таких языка (русский + французский + английский и
т.д.) - это, извините, уже слишком...
Решений, конечно, существует множество, но все они обладают как
преимуществами, так и заметными недостатками. Поэтому выбор конкретного
способа сильно зависит от обстоятельств : от автора, от предполагаемой
аудитории с учетом ее географического положения, от времени, которым
располагает веб-мастер, от его любимого программного обеспечения и т. д.
Чтобы сделать наш выбор осознанным, а не действовать методом "научного
тыка", давайте уделим внимание кодовым таблицам, определяющим, как будет
отображаться наш документ.
При вводе текста в компьютер каждая буква (знак) представляется числовым
кодом, который назначен ей в соответствии с тем или иным стандартом - кодовой
таблицей. Именно эти коды хранятся в текстовых файлах и передаются по сети.
Когда же, в конце, концов дело доходит до отображения текста (не важно, на
экране или на принтере), этим кодам снова должны быть сопоставлены знаки. И
горе вам, если это сопоставление будет выполняться по другому стандарту.
А ведь если не позаботиться об этом специально, то скорее всего так и
случится. Дело в том, что еще с весьма давних времен для кодирования одного
знака в тексте стали выделять восемь битов - один байт. Это позволяет
использовать в тексте не более 256 различных знаков. Причем половина мест
изначально зарезервирована под латиницу, цифры, знаки препинания и всякие
технические символы. Оставшихся 128 позиций при всем желании не хватит на все
существующие в мире алфавитные языки (европейские, русский, иврит, арабский,
армянский, грузинский и др.). Поэтому для каждого языка без оглядки на другие
стали создавать свои кодовые таблицы.
Как буква появляется на экране
Теперь представьте себе, что происходит, когда текст, созданный с
использованием французской кодовой таблицы, а воспроизводится - по русской.
Вместо французских букв выводятся русские с совпадающими кодами. Чтобы этого
не случалось , в заголовке HTML-документа обязательно нужно указывать
используемую кодовую таблицу. Делается это соответствующим тегом вида
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=Windows-1251">
Запись Windows-1251 как
раз и указывает броузеру, что в документе использована русская кодировка,
применяемая в Windows. Получив такое явное указание, даже французский броузер
все коды символов будет интерпретировать по русской кодовой таблице. К
сожалению, это относится и к французским символам, если таковые были
вставлены в текст. В самом деле, их ведь нельзя отличить от русских - коды-то
совпадают.
Чтобы справиться с этой проблемой , символы, которые не укладываются в
выбранную кодовую таблицу следует записывать специальными кодовыми
наименованиями. В тексте HTML-документа они начинаются знаком амперсенда и
оканчиваются точкой с запятой. Это, конечно, не очень удобно, но, по крайней
мере, естественно. Мы будем называть такие обозначения &- цепочками.
К сожалению, на деле не все так просто. Для правильного отображения букв
мало того, чтобы они корректно были записаны в документе, нужно еще чтобы
броузер сумел их воспроизвести. А ему для этого понадобятся шрифты, то есть
файлы, в которых хранятся изображения нужных литер. К счастью , основные
шрифты (Times, Courier, Arial и некоторые другие), используемые в современных
версиях Windows, содержат довольно обширный набор символов. Кроме кириллицы ,
в них есть все символы, используемые в европейских языках, греческие и даже
арабские буквы.
Unicode
Проницательный читатель должен на этом месте заинтересоваться, а как же
кодируются в файлах шрифтов все эти многочисленные знаки, ведь 256 позиций
для этого совершенно недостаточно. Этот вопрос естественным образом приводит
нас к разговору о кодировке Unicode, которая медленно, но верно завоевывает
популярность в компьютерном мире. В Unicode каждый символ кодируется не
одним, а двумя байтами, что позволяет расширить кодовую таблицу до 65536
символов. В такое кодовое пространство свободно помещаются все известные
алфавиты, специальные профессиональные знаки и даже японские, китайские и
корейские иероглифы. Для каждого символа найдется свой код.
Располагая такими шрифтами , броузер с легкостью может отобразить текст
на любой смеси языков. Но только для этого он должен быть уверен, что
имеющиеся в его распоряжении шрифты все эти языки поддерживают. Ведь на
практике в файле шрифта могут храниться изображения символов далеко не для
всех кодовых позиций. И вот тут-то и выясняется, что два наиболее
распространенных броузера - MS Internet Explorer и Netscap e Navigator -
демонстрируют весьма различную степень самоуверенности.
Различие Internet Explorer и Netscape Navigator
Так, Explorer считает, что в вопросе отображения символов можно полностью
положиться на шрифты. В крайнем случае, если заказанного символа в нужной
позиции выбранного шрифта не окажется, Explorer выведет вместо него пустой
квадратик. Иное поведение демонстрирует Navigator. Он строго ограничивается
символами, входящими в заказанную кодовую таблицу. На месте любых других
символов выводится знак вопроса. При этом наличие изображения символа в
используемом шрифте даже не проверяется. Вероятно, такой осторожный подход
вызван тем, что Navigator - многоплатформенная программа, а Explorer работает
только в Windows и на Макинтоше (Macintosh).
В конечном счете, каковы бы ни были причины, результат на экране
получается не в пользу Netscape. Если в заголовке документа указана русская
кодовая таблица, то французские буквы вам не светят, и наоборот.
Однако возможность отобразить многоязычный текст есть и в Netscape
Navigator. Для этого в качестве кодовой таблицы нужно указать UTF-7 или
UTF-8, то есть непосредственно сам Unicode. В этом случае Navigator корректно
покажет и русские , и французские , и даже греческие и многие другие буквы
(если, напомним, установлен универсальный шрифт. Но, к сожалению, все
символы, кроме латиницы, цифр и знаков препинания (с ASCII- кодами до 128),
вам придется задавать их названиями или номерами по кодировке Unicode, то
есть в виде é или й . Невеселая перспектива для
русско-французского сайта - мало того что размер документов вырастет в
несколько раз, но еще и читать исходные тексты такого сайта становится почти
невозможно. Остается одно утешение - такой сайт будут одинаково хорошо
отображать и Explorer, и Netscape.
UTF-7 и UTF-8
Кстати, тут самое время коснуться одного тонкого различия между
кодировками UTF-7 и UTF-8, знать о котором полезно, если вы хотите уменьшить
размер страниц, и так раздувшихся из-за громоздкого представления символов.
Выше уже говорилось, что в Unicode каждый символ кодируется двумя байтами.
Многие и это считают расточительным, но в таком случае тратить на каждый
символ по шесть-восемь байтов - сущее мотовство. Тем не менее при
использовании кодировки UTF-7 других вариантов нет. Зато UTF-8 позволяет
кодировать символы национальных алфавитов всего двумя байтами. При этом
латиница и цифры по-прежнему укладываются в один байт. В результате размер
файла растет только в 1,5-2 раза. Именно в таком формате сохраняет
многоязычные файлы Netscape Composer, да и многие другие HTML- редакторы,
поддерживающие работу с многоязычными текстами.
Правда, файл в кодировке UTF-8 уже с трудом можно назвать текстовым.
Открывать его при помощи Notepad - гиблое дело. Для работы с такими файлами
нужны специальные программы. Если Composer и другие WYSIWYG- программы по
известным причинам вас не устраивают, то можно посоветовать UnicEdit
(http://www.heiner-eichmann.de/software/unicedit/unicedit.htm). Это простой
текстовый редактор, работающий c файлами UTF-8, но, к сожалению, пользоваться
им можно только в Windows NT 4.0.
Варианты записи букв
Подводя итог нашему обширному теоретическому экскурсу, составим сводку
методов представления национальных литер в HTML- документах и отметим их
совместимость с современными версиями броузеров.
Французские буквы
Возьмем для примера разновидности буквы e:
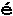 - "e accent aigu",
- "e accent aigu",
 - "e accent circonflexe",
- "e accent circonflexe",
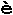 - "e accent grave".
В таком порядке они и следуют в примерах ниже:
- "e accent grave".
В таком порядке они и следуют в примерах ниже:
1. Можно прямо в файле HTML написать, если клавиатура и шрифт позволяют,
,
то есть просто буква в букву.
А при неверных настройках вы увидите на экране й к и.
2. "Описательный способ" определения букв: é ê è
3. По номерам Unicode: è é ê
Варианты 2 и 3 во всех известных нам случаях дают одинаковые результаты,
хотя вариант 2 считается более надежным, так как дает прямое описание самой буквы,
а не ее места в таблице.
Русские буквы
Годятся все вышеприведенные способы 1 - 3: буквы переходят в русские
( й к и соответственно) сменой шрифта и кодировки.
4. Дополнительный "русский путь": п р о
В этом варианте "неправильные" буквы, то есть не ожидаемые русские й к и, не получаются.
Возможны либо правильные, либо никакие: пустое место, знак вопроса, квадратик.
Зато вообще неважно, что написано в
<META ... charset ...">
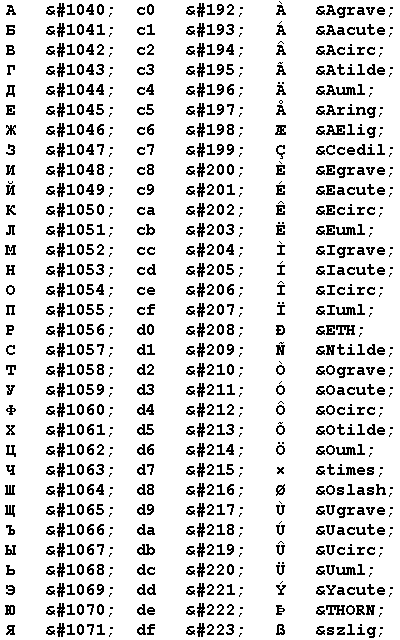
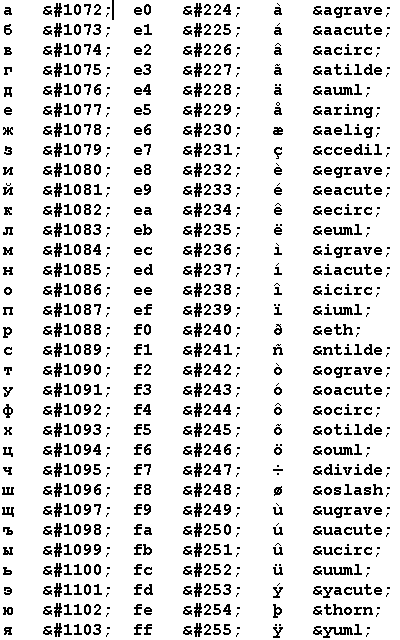
Таблица кодировок
В таблице приводятся коды русских и западноевропейских букв
(а также ряда других символов, естественным путем в нее попавших),
причем на одной строке располагаются буквы, которые занимают одну и ту же позицию
в кодовых страницах Windows-1251 и Windows-1252.
Если кодовая страница перепутана, а также в старых версиях броузеров
эти буквы могут заменять друг друга.
Иными словами, й никогда не станет буквой
,
но у них есть общий родственник - é, который в зависимости от параметра charset,
настроек броузера и наличия шрифтов превращается то в й,
то в .
Естественно, при использовании русской кодовой страницы, отличной от Windows-1251
(например, KOI8-R), соответствие русских и европейских букв установится иначе.
Обозначения:
Pус - русская буква;
UTF - код буквы по стандарту Unicode (UTF-8)
Win - код буквы русской буквы по кодовой странице Windows-1251
и соответствующей европейской буквы по кодовой странице Windows-1252.
Эти же коды использует MS Word в файлах RTF.
Они также применяются в кодировке quoted-printable.
UTF - во второй колонке UTF представлены коды западноевропейских букв по стандарту Unicode.
Euro - европейские буквы.
HTML - имя европейской буквы в языке HTML.
Для удобства читателя приводим эту таблицу в виде HTML - файла.
Вы можете испытать ваш броузер, воспроизводя интересующие вас строки
и пробуя задавать разные параметры тега charset, а также параметр FONT FACE.
.
<HTML >
<HEAD>
<TITLE>Русский текст</TITLE>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-7">
</HEAD>
<BODY>
<PRE>
 </PRE>
</BODY>
</HTML>
</PRE>
</BODY>
</HTML>
| |
|
Допустимые кодовые страницы |
| Способ записи |
Примеры |
Internet Explorer |
Netscape Navigator |
| Обычный набор "буква в букву" |
й |
Соответствующая национальная* |
Соответствующая национальная |
| Названия букв в виде &- цепочек |
é |
Любая |
UTF-7, UTF-8** |
| Коды по Unicode в формате &- цепочек |
è
п |
| Двухбайтовое двоичное кодирование |
C3 A8
D0 BF |
UTF-8 |
* Европейские литеры также правильно воспроизводятся в кодировке UTF-7
** При задании национальной кодовой таблицы правильно отображается только
входящие в нее буквы.
Как видно из таблицы, единственный универсальный метод - это
использование кодировки UTF-8. Но, как мы уже отмечали, ее довольно неудобно
редактировать. Как же быть, если нужно создать универсальный сайт, а возиться
с UFT-8 очень не хочется ? Неужели нет подходящего метода?
Такой метод, конечно существует, но вот воспользоваться им без помощи
квалифицированного web -мастера и современного сервера не получится. Идея
состоит в том, чтобы web-сервер формировал разные страницы для разных
броузеров. Тогда хранить страницы сайта можно, например, в кодировке
Windows-1251, но при получении запроса от Netscape Navigator конвертировать
их в UTF-7 или UTF-8.
Проблемы ветеранов
Отдельного упоминания заслуживают старые (третьи) версии броузеров.
Поскольку они не умеют работать с Unicode, то указание кодовых таблиц UTF-7 и
UTF-8 они просто игнорируют.
Как следствие , Netscape Navigator 3.0 практически не способен отображать
тексты на смеси языков, хотя в случае крайней необходимости этого можно
добиться явным указанием в тегах <FONT FACE=...> соответствующих
шрифтов для символов, выпадающих из объявленной в заголовке национальной
кодовой таблицы. Нужно только предварительно позаботиться, чтобы у всех
пользователей эти шрифты имелись. К счастью, эта версия Navigator практически
никем уже не используется.
Зато Internet Explorer третьей версии периодически встречается,
так как по умолчанию устанавливается вместе с Windows 95. Несмотря на незнание
Unicode , он успешно справляется с отображением национальных литер, если они
указываются по именам с помощь &- цепочек. Однако буквы , заданные
номерами , он отображает по-разному в зависимости от выбранной кодовой
таблицы, так что пользоваться этим способом для IE3 не следует.
Еще один интересный факт, касающийся IE3, немало удивил нас - он
единственный из семейства Explorer сумел корректно распечатать на принтере
страницу на смеси языков. Старшие версии при печати теряют диакритические
знаки, даже если они корректно отображались на экране. В то же время все
версии Netscape справляются с этой задачей безупречно.
Практика многоязычного HTML
Основные результаты
1. Итак, для Netscape Navigator 3 нет приемлемых решений для совмещения
русского и французского языков в пределах одного HTML-файла .
2. В старших версиях Netscape задача решается использованием кодировок
UTF-7 и UTF-8, но файлы в этих кодировках значительно увеличиваются в
размерах (в 4-5 и 1,5-2 раза соответственно) и становятся неудобными для
редактирования.
3. Во всех версиях Internet Explorer (3, 4, 5) работает описанное в
начале статьи простое решение (русский - буква в букву, французский - в виде
&- цепочек ).
4. Для просмотра смешанных текстов пригоден довольно большой набор
шрифтов, в том числе самые ходовые в Windows: Times New Roman, Courier,
Arial и ряд других. Не годятся устаревшие шрифты, унаследованные от Windows
3.1x, в которых используется 8-битные коды символов. Поэтому во избежание
неприятностей лучше не злоупотреблять экзотическими шрифтами.
Плодить ли версии?
Поскольку версия для Internet Explorer получается простая и удобная, а
для Netscape Navigator - сложная и неповоротливая, то ответьте для себя на
следующие вопросы:
1. Есть ли у вас , как у веб-мастера, время и желание, создав все
необходимое для Internet Explorer, заниматься дополнительным перекодированием
для Netscape?
2. Есть ли на сервере место, чтобы хранить файлы для Netscape, которые
значительно больше, чем исходные для Explorer.
3. Есть ли у пользователя время загружать эти файлы?
4. Может ли ваш сервер выдавать пользователю файлы в кодировке UTF-7 или
UTF-8 в исходном виде? Есть "умные" серверы, которые считают, что содержат
документы только в КОИ-8, и самовольно перекодируют все остальное. А что
будет, если вы такие документы UTF-8 пересылаете по электронной почте?
5. Читают ли вас во Франции, где по числу пользователей Internet
Explorer многократно превосходит Netscape Navigator?
HTML-редакторы
Если до сих пор мы в основном обсуждали, каким должен быть многоязычный
HTML- файл, то теперь посмотрим на нескольких примерах, как его можно
сделать. Основная проблема любых перекодировок и преобразований многоязычного
текстового документа в том, что становятся неразличимы буквы
й-,
и-,
к- и т.п.,
то есть конверсия ведет к необратимой потере информации.
MS Word 97
Word очень удобен для подготовки многоязычных документов.
Но, чтобы не утратить драгоценную языковую информацию при экспорте в формат HTML,
нужно обязательно выбрать сохранение файла в кодировке UTF-8. В противном случае пары букв
й-,
и-,
к- и т.п.,
будут необратимо смешиваться. Впрочем, если,
сохраняя многоязычный документ в формате HTML, вы забудете указать кодировку
UTF-8, Word сам предупредит вас об этом и предложит вернуться, чтобы сделать
правильный выбор. Но все это сработает только в случае, если Word был правильно установлен!
Если кодировка UTF-8 вас не устраивает и вы хотите получить файл с
русской кодовой таблицей, то перед экспортом нужно контекстной заменой
подставить вместо французских букв соответствующие им &- цепочки, а затем
в экспортированном HTML- файле с помощью обычного текстового редактора
заменить все цепочки вида &# на сочетание &#. Но пользуясь
этим приемом , не забывайте, что такое преобразование необратимо, и снова
загрузить такой файл в Word для редактирования будет невозможно.
Page Maker 6.5
Нам не удалось найти опции, позволяющие правильно конвертировать
русско-французский текст из PageMaker в HTML. Если текст представляет собой
чередующиеся русские и французские фрагменты разумного размера, то один из
вариантов - конвертировать файл дважды: "по-русски" и "по-французски", после
чего собрать результат по кусочкам. Можно также воспользоваться описанной
выше процедурой с контекстными заменами.
Front Page
Как оказалось, UTF-8 - единственная кодировка, в которой можно работать с
многоязычными текстами, причем она обязательно должна быть явно указана в
<META HTTP ...> . Русско-французские комбинации в любых остальных
кодировках не выживают.
Netscape Composer 4.x
В кодировках типа "смесь русского с é" он необратимо изменяет
либо русские буквы, либо accents, превращая их в знаки вопроса. Работать с
русско-французским текстом удается только в кодировках UTF-7 и UTF-8 (они
должны быть объявлены в заголовке файла). Причем в таких файлах Composer, как
и другие рассмотренные редакторы, заменяет &- цепочки на двухбайтные
коды. Это исключает возможность непосредственно q работы с кодом страницы при
помощи обычного текстового редактора. Кроме того, он вставляет огромное
количество лишних повторяющихся тегов, раздувая и замусоривая файл изнутри.
WebExpert 2000
Известный среди франкоязычных вебмастеров продукт для создания
веб-документов (есть также английская версия - см. www.visic.com) .
Его удобство - в том, что работа идет только
с кодом, а результат показывается в отдельном окне. Кроме того, он при
чтении-записи не производит самовольного преобразования кода.
Во французской версии можно работать прямо с русским текстом,
а для accents есть удобная функция "вставки спецсимволов" в виде &- цепочек (é ê è и т.д ).
Есть у него и ряд недостатков. Так, операция Import RTF плохо
воспринимает accents и совсем неприемлема для русских букв. Операция
"конверсия спецсимволов", преобразующая accents в é преобразует в
них же и русские буквы. Поведение WebExpert по отношению к русским буквам
обладает и другими странностями.
У его англоязычной версии - AceHTML 4.x - странностей и неудобств на эту тему
еще больше. Правда, в отличие от французской, она бесплатная.
Мы перепробовали также много комбинаций типа "создать файл в Netscape Composer -
добавить один пробел в Front Page - просмотреть в Internet Explorer" при разнообразных кодировках.
Составленная по признаку "проходит - не проходит" таблица поражает своей пестротой
и полным отсутствием разумных закономерностей (поэтому мы ее и не приводим,
но готовы прислать всем желающим).
Отсюда следует:
1. Ни в коем случае не надо комбинировать средства создания веб-страниц,
то есть не сочетать ни разные редакторы WYSIWYG друг с другом, ни WYSIWYG со
средствами типа Notepad.
2. Настоятельно рекомендовать пользоваться Internet Explorer.
3. Работать на основе русского текста, вставляя accents в виде &-цепочек.
4. При операциях типа Export - Import HTML применять к французским буквам "обходные маневры".
Выводы
Фактически есть два относительно стабильных подхода к работе с
многоязычными HTML- страницами. Первый состоит в том, чтобы пользоваться
кодовой страницей преобладающего языка, вставляя символы других языков с
помощью &-цепочек. В этом случае страницы удобно редактировать в обычных
текстовых редакторах и в HTML- редакторах, ориентированных на работу с
исходным кодом страницы, таких, например, как HomePage, 1st Page 2000 или
WebExpert. Получаемые страницы можно просматривать только в Internet
Explorer. Причем, если предполагается задействовать его третью версию
(например, для распечатки страниц), то в &- цепочках должны
использоваться только имена букв, но не их коды. Понятно, что такой подход не
годится для серьезного профессионально сделанного web- сервера, зато он очень
удобен для небольших приватных сайтов.
Альтернативный подход состоит в том, чтобы полностью и безоговорочно
перейти на кодировку UTF-8. В этом случае вы соглашаетесь, что размер файлов
несколько увеличивается, а для редактирования страниц нужно пользоваться
только такими редакторами, которые понимают этот формат. Это могут быть как
WYSIWYG- программы, типа FrontPage, Composer, Word, так и обычные текстовые
редакторы типа упоминавшегося выше UnicEdit. Зато такой подход обеспечивает
максимальную универсальность. Сайт будет правильно просматриваться в любом
достаточно современном броузере, в частности в четвертых и более старших
версиях Internet Explorer и Netscape Navigator . Единственная неприятность
связана с ошибкой в Explorer, из-за которой нельзя корректно распечатывать
страницы такого сайта. Но в Netscape эта проблема отсутствует.